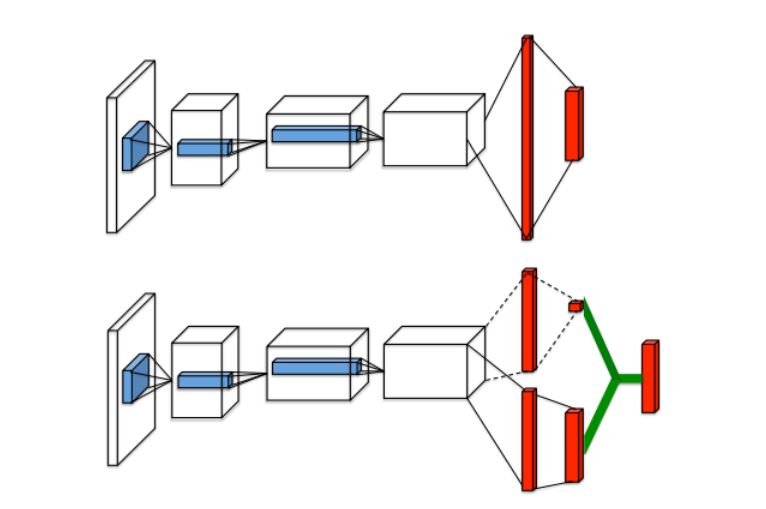
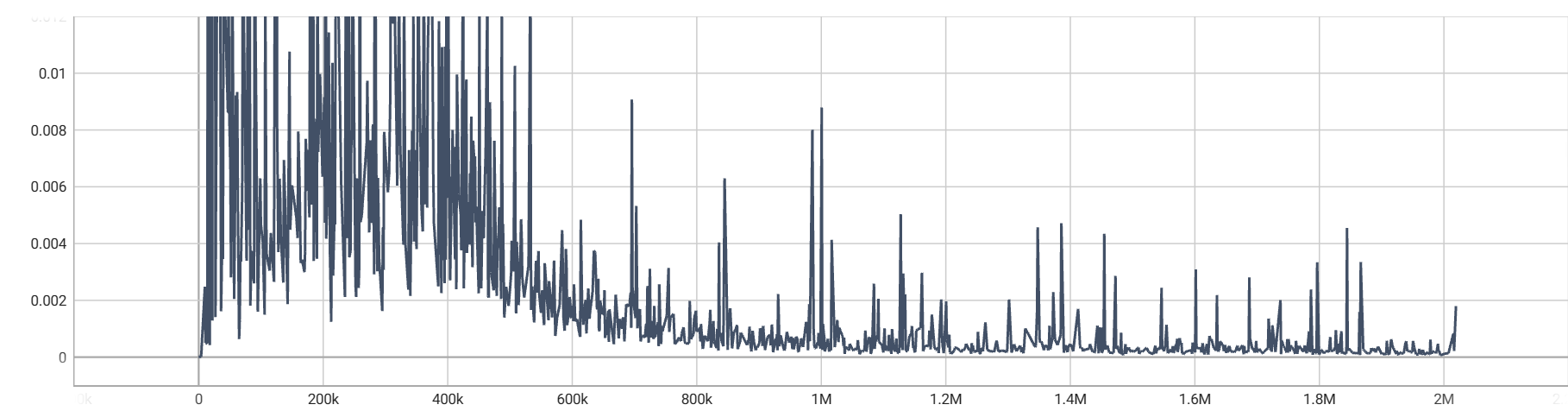
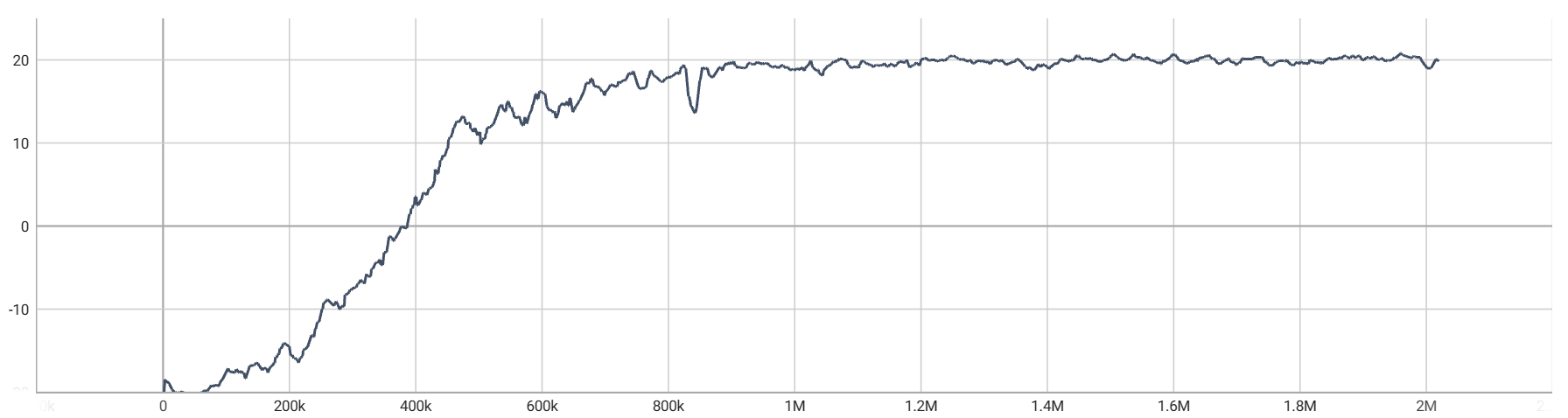
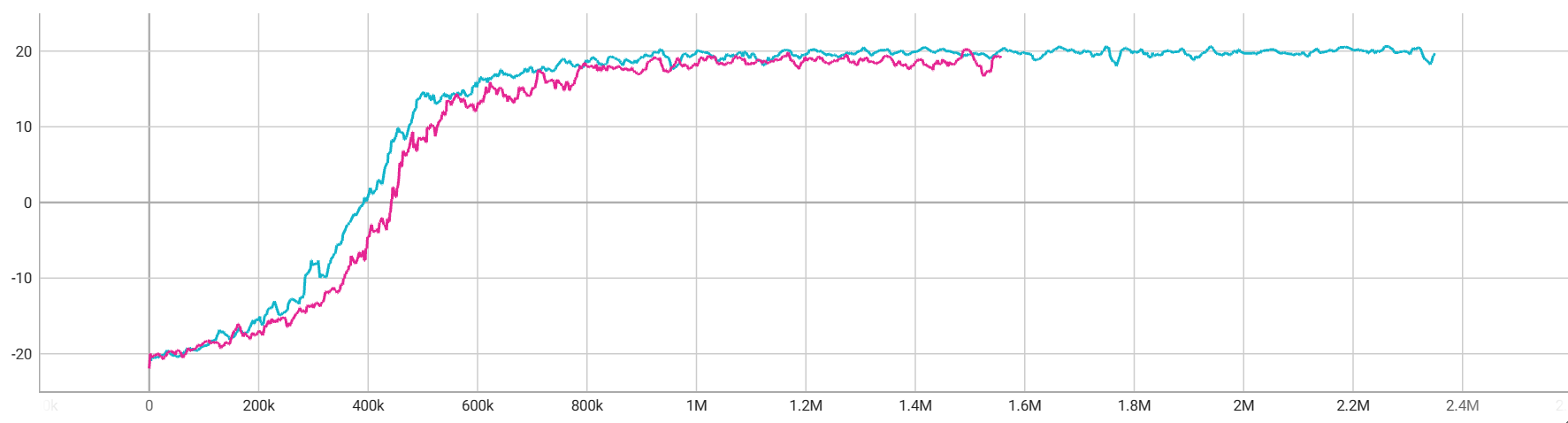
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
| import random
import torch
class Transition(object):
'''
the order is frame action reward next_frame done
'''
def __init__(self, frame, action, reward, next_frame, done, priority=0, index=0):
self.priority = priority
self.index = index
self.content = (frame, action, reward, next_frame, done)
def __lt__(self, other):
return self.priority < other.priority
def __gt__(self, other):
return self.priority > other.priority
def __str__(self):
return f'priority: {self.priority}, index: {self.index}'
class MPriorityQueue:
def __init__(self, max_size=10000):
self.heap = []
self.max_size = max_size
def push(self, item):
self.heap.append(item)
self._heapify_up(len(self.heap) - 1)
while (len(self.heap) > self.max_size):
self.pop()
def pop(self):
if len(self.heap) == 0:
return None
if len(self.heap) == 1:
return self.heap.pop()
root = self.heap[0]
self.heap[0] = self.heap.pop()
self._heapify_down(0)
return root
def update_key(self, index: int, new_key):
if index < 0 or index >= len(self.heap):
return
old_key = self.heap[index].priority
self.heap[index].priority = new_key
if new_key > old_key:
self._heapify_down(index)
def _heapify_up(self, index):
parent_index = (index - 1) // 2
if index > 0 and self.heap[index] > self.heap[parent_index]:
self.heap[index], self.heap[parent_index] = self.heap[parent_index], self.heap[index]
self._heapify_up(parent_index)
def _heapify_down(self, index):
left_child_index = 2 * index + 1
right_child_index = 2 * index + 2
largest = index
if (left_child_index < len(self.heap) and
self.heap[left_child_index] > self.heap[largest]):
largest = left_child_index
if (right_child_index < len(self.heap) and
self.heap[right_child_index] > self.heap[largest]):
largest = right_child_index
if largest != index:
self.heap[index], self.heap[largest] = self.heap[largest], self.heap[index]
self._heapify_down(largest)
class SortedList:
def __init__(self, max_size=10000):
self.heap = []
self.max_size = max_size
def push(self, item):
self.heap.append(item)
if len(self.heap) > 2 * self.max_size:
self.sort()
def sort(self):
print('sort')
self.heap.sort(key=lambda x: x.priority, reverse=True)
while (len(self.heap) > self.max_size):
self.pop()
def pop(self):
if len(self.heap) == 0:
return None
return self.heap.pop()
def update_key(self, index: list, new_key: list):
for idx, key in zip(index, new_key):
for item in self.heap:
if item.index == idx:
item.priority = key
break
class PriorityReplayBuffer:
"""
A replay buffer class for storing and sampling experiences for reinforcement learning.
Args:
size (int): The maximum size of the replay buffer.
Attributes:
size (int): The maximum size of the replay buffer.
buffer (list): A list to store the experiences.
cur (int): The current index in the buffer.
device (torch.device): The device to use for tensor operations.
Methods:
__len__(): Returns the number of experiences in the buffer.
transform(lazy_frame): Transforms a lazy frame into a tensor.
push(state, action, reward, next_state, done): Adds an experience to the buffer.
sample(batch_size): Samples a batch of experiences from the buffer.
"""
def __init__(self, size, alpha):
self.alpha = alpha
self.size = size
self.cur = 0
self.max_priority = 0
self.device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
self.q = SortedList(max_size=size)
def __len__(self):
return len(self.q.heap)
def transform(self, lazy_frame):
state = torch.from_numpy(lazy_frame.__array__()[None] / 255).float()
return state.to(self.device)
def push(self, state, action, reward, next_state, done):
"""
Adds an experience to the replay buffer.
Args:
state (numpy.ndarray): The current state.
action (int): The action taken.
reward (float): The reward received.
next_state (numpy.ndarray): The next state.
done (bool): Whether the episode is done.
"""
trans = Transition(frame=state, action=action, reward=reward, next_frame=next_state, done=done,
priority=self.max_priority + 1, index=self.cur)
self.max_priority += 1
self.q.push(trans)
self.cur += 1
def get_index(self, batch_size):
self.weight = [1 / ((i + 1) ** self.alpha) for i in range(len(self.q.heap))]
t = sum(self.weight)
self.weight = [w / t for w in self.weight]
return random.choices(range(len(self.q.heap)), self.weight, k=batch_size)
def get_weight(self, index):
max_prob = max(self.weight)
ret = [self.weight[i] / max_prob for i in index]
return ret
def sample(self, batch_size, index):
"""
Samples a batch of experiences from the replay buffer.
Args:
batch_size (int): The size of the batch to sample.
Returns:
tuple: A tuple containing the batch of states, actions, rewards, next states, and dones.
"""
states, actions, rewards, next_states, dones = [], [], [], [], []
for idx in index:
frame, action, reward, next_frame, done = self.q.heap[idx].content
state = self.transform(frame)
next_state = self.transform(next_frame)
state = torch.squeeze(state, 0)
next_state = torch.squeeze(next_state, 0)
states.append(state)
actions.append(action)
rewards.append(reward)
next_states.append(next_state)
dones.append(done)
return (torch.stack(states).to(self.device), torch.tensor(actions).to(self.device),
torch.tensor(rewards).to(self.device),
torch.stack(next_states).to(self.device), torch.tensor(dones).to(self.device))
def update_priority(self, index, td_error):
self.q.update_key(index, td_error)
self.max_priority = max(self.max_priority, max(td_error))
if __name__ == '__main__':
sl = SortedList()
for i in range(10):
t = Transition(priority=i, index=i)
sl.push(t)
sl.update_key([5, 2], [10, 20])
for trans in sl.heap:
print(trans)
t = Transition(priority=-10, index=-1)
sl.push(t)
t = Transition(priority=-2, index=-2)
sl.push(t)
sl.update_key([-2, 2], [30, 20])
sl.sort()
for trans in sl.heap:
print(trans)
|